شبکههای عصبی بزرگ امروزه در مرکز اصلی بسیاری از پیشرفتهای اخیر در هوش مصنوعی هستند، اما آموزش آنها یک چالش مهندسی و تحقیقاتی دشواری است که مستلزم هماهنگسازی خوشهای از پردازنده های گرافیک و یا همان GPUها برای انجام یک محاسبات همگامسازی شده است. با افزایش اندازه خوشه و مدل، متخصصان یادگیری ماشینی تنوع فزایندهای از تکنیکها را برای موازی کردن آموزش مدل در بسیاری از GPUها توسعه دادهاند. در نگاه اول، درک این تکنیکهای موازی ممکن است دلهرهآور به نظر برسد، اما تنها با چند فرض در مورد ساختار محاسبات، این تکنیکها بسیار واضحتر میشوند – در آن مرحله، شما فقط در حال جابجایی در اطراف بیت های مبهم از A به B هستید، مانند سوئیچ شبکه که در اطراف بسته ها(packets) جابه جا می شود.
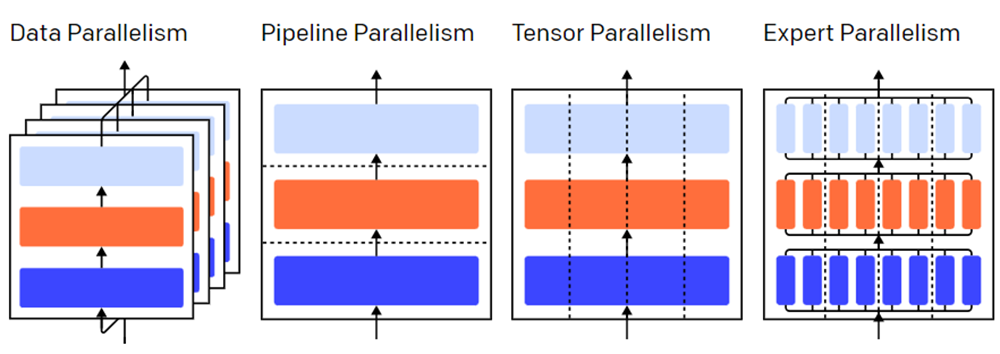
تصویری از استراتژیهای مختلف موازیسازی در یک مدل سه لایه. هر رنگ به یک لایه اشاره دارد و خطوط نقطه چین پردازندههای گرافیکی مختلف را از هم جدا میکنند.
بدون موازی سازی
آموزش شبکه عصبی یک فرآیند تکرار شونده است. در هر تکرار، ما از لــایــههای یک مدل عبور میکنیم تا خروجی را برای هر نمونه آموزشی در دستهای از دادهها محاسبه کنیم. سپس عبور دیگری از لایهها به سمت عقب انجام میشود و میزان تأثیر هر پارامتر بر خروجی نهایی را با محاسبه گرادیان نسبت به هر پارامتر منتشر میکند.متوسط گرادیان برای دسته، پارامترها، و مقداری از حالت بهینهسازی در هر پارامتر به یک الگوریتم بهینهسازی مانند Adam منتقل میشود، که پارامترهای تکرار بعدی (که باید عملکرد کمی بهتر بروی دادههای شما داشته باشد) و هر پارامتر جدید را محاسبه میکند. و در حالت بهینه سازی، همانطور که آموزش بر روی دستهای از دادهها تکرار میشود، مدل برای تولید خروجیهای دقیقتر تکامل مییابد.
تکنیکهای مختلف موازی، این فرآیند آموزشی را در ابعاد مختلفی تقسیم میکنند، که عبارتند از:
- موازی سازی دادهها – اجرای زیر مجموعههای مختلفی از دسته بر روی پردازنده های گرافیکی.
- موازی سازی خط لوله – لایه های مختلف مدل را روی GPU های مختلف اجرا کنید.
- موازی سازی تنسور – ریاضیات را برای یک عملیات واحد مانند ضرب ماتریس برای تقسیم در GPUها تجزیه کنید.
- ترکیبی از بهترینها – هر نمونه را تنها با کسری از هر لایه پردازش کنید.
(در این پست، فرض میکنیم که شما از GPU برای آموزش شبکههای عصبی خود استفاده میکنید، اما همین ایدهها برای کسانی که از هر شتابدهنده شبکههای عصبی دیگری استفاده میکنند نیز صدق میکند.)
استفاده از موازی سازی
آموزش موازی داده به معنای کپی کردن پارامترهای یکسان در چندین GPU (اغلب “بخش فعال”) و تخصیص نمونههای مختلف به هر یک برای پردازش همزمان است. موازی سازی داده ها به تنهایی مستلزم این است که مدل شما در حافظه یک GPU قرار گیرد، اما به شما این امکان را می دهد که محاسبات بسیاری از GPU ها به بهای ذخیره کپی های تکراری زیادی از پارامترهای خود استفاده کنید. همانطور که گفته شد، استراتژیهایی برای افزایش RAM موثر موجود برای GPU شما وجود دارند، مانند بارگذاری موقت پارامترها در حافظه CPU در بین استفاده از حافظه GPU.
از آنجایی که هر بخش فعال موازی، داده نسخه کپی خود را از پارامترها به روز میکند، باید هماهنگ شوند تا اطمینان حاصل شود که هر بخش فعال همچنان پارامترهای مشابهی را دارد. سادهترین روش، معرفی مسدود کننده ارتباط بین بخشهای فعال است: (1) به طور مستقل گرادیان را بر روی هر بخش فعال محاسبه کنید. (2) میانگین شیب در بین بخشهای فعال. و (3) به طور مستقل همان پارامترهای جدید را بر روی هر بخش فعال محاسبه کنید. مرحله (2) یک میانگین وقفهای است که نیاز به انتقال اطلاعات بسیار زیادی دارد (که متناسب است با تعداد بخشهای فعال و اندازه پارامترهای شما)، که می تواند به توان عملیاتی آموزشی شما آسیب برساند. طرحهای هماهنگسازی ناهمزمان مختلفی برای حذف این سربار وجود دارد، اما آنها به کارایی و بهره یادگیری آسیب میزنند. در عمل، مردم عموماً به رویکرد همزمان و همگام پایبند هستند.
موازی سازی خطوط لوله
با آموزش موازی خط لوله، ما تکههای متوالی مدل را در بین GPU ها تقسیم میکنیم. هر GPU فقط یکسری از پارامترها را در خود جای میدهد، بنابراین همان مدل حافظه کمتری را برای هر GPU مصرف میکند.
تقسیم یک مدل بزرگ به تکههای لایههای متوالی کار سادهای است. با این حال، یک وابستگی متوالی بین ورودیها و خروجیهای لایهها وجود دارد. بنابراین یک پیادهسازی سادهلوحانه میتواند منجر به مقدار زمان بیحرکتی زیادی شود، در حالی که بخش فعال منتظر خروجیهای ماشین قبلی میباشد تا به عنوان ورودی آن استفاده شود. این تکههای زمان انتظار به عنوان «حباب» شناخته میشوند، که محاسباتی را که میتوانستند توسط ماشینهای غیر فعال انجام دهند، تلف میکنند.
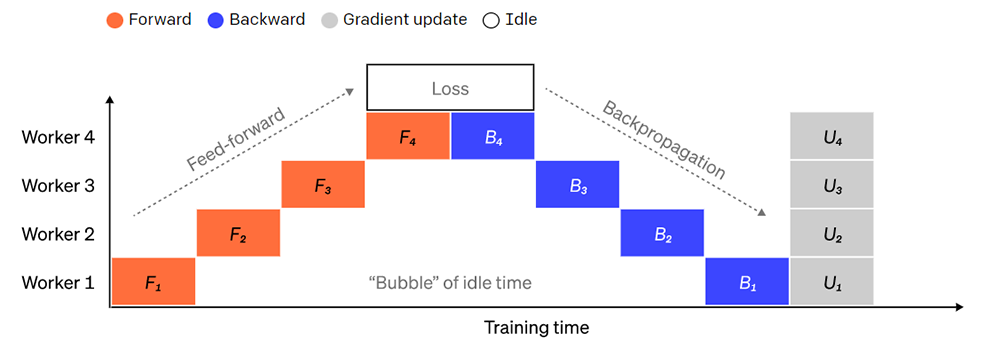
تصویری از یک موازی سازی خط لوله ساده که در آن مدل به صورت عمودی به 4 پارتیشن به صورت لایه تقسیم می شود. Worker 1 میزبان پارامترهای مدل اولین لایه شبکه (نزدیک ترین به ورودی) است، در حالی که Worker 4 میزبان لایه 4 (که نزدیک ترین به خروجی است) است. “F”، “B” و “U” به ترتیب نشان دهنده عملیات رو به جلو، عقب و به روز رسانی است. زیرمجموعه ها نشان می دهند که عملیات بر روی کدام بخش فعال با همان Worker اجرا میشود. دادهها به دلیل وابستگی متوالی توسط یک کارگر در یک زمان پردازش میشوند که منجر به “حباب” بزرگ در هنگام زمان بیکاری و یا غیر فعالی میشود.
ما میتوانیم از ایدههای موازیسازی دادهها برای کاهش هزینه حباب استفاده کنیم، زیرا هر کارگر فقط زیرمجموعهای از عناصر داده را در یک زمان پردازش میکند و به ما این امکان را میدهد که محاسبات جدید را با زمان انتظار همپوشانی هوشمندانه داشته باشیم. ایده اصلی این است که یک دسته را به چند میکروبچ تقسیم کنیم. هر میکروبچ باید به نسبت سریعتر پردازش شود و هر کارگر به محض اینکه در دسترس قرار گرفت، کار روی میکروبچ بعدی را شروع میکند، بنابراین اجرای خط لوله را تسریع میکند. با میکروبچ های کافی، کارگران را می توان در بیشتر مواقع با حداقل حباب در ابتدا و انتهای مرحله استفاده کرد. گرادیان ها در میکروبچ ها به طور میانگین محاسبه می شوند و به روز رسانی پارامترها تنها زمانی اتفاق می افتد که همه میکروبچ ها تکمیل شوند.
ما میتوانیم از ایدههای جودود در موازیسازی دادهها برای کاهش ارزش حباب استفاده کنیم، زیرا هر کارگر فقط زیرمجموعهای از عناصر داده را در یک زمان پردازش میکند و به ما این امکان را میدهد که محاسبات جدیدی را با مدت زمان انتظار همپوشانی هوشمندانه ای داشته باشیم. ایده و نیت اصلی این است که یک دسته را به چند میکروبَچ تقسیم کنیم. هر میکروبچ نسبتا باید سریعتر پردازش شود و هر بخش فعال و با همان Worker به محض اینکه در دسترس قرار گرفت، کار روی میکروبچ بعدی را شروع میکند، بنابراین اجرای خط لوله را تسریع میکند. با میکروبچهای کافی، بخشهای فعال را میتوان در بیشتر مواقع با حداقل حباب در ابتدا و انتهای مرحله استفاده کرد. گرادیانها در میکروبچها به طور میانگین محاسبه میشوند و به روز رسانی پارامترها تنها زمانی اتفاق خواهد افتاد که همه میکروبچ ها تکمیل شوند.
تعداد بخشهای فعالی که مدل بر روی آنها تقسیم میشود معمولاً به عنوان عمق خط لوله شناخته میشود.
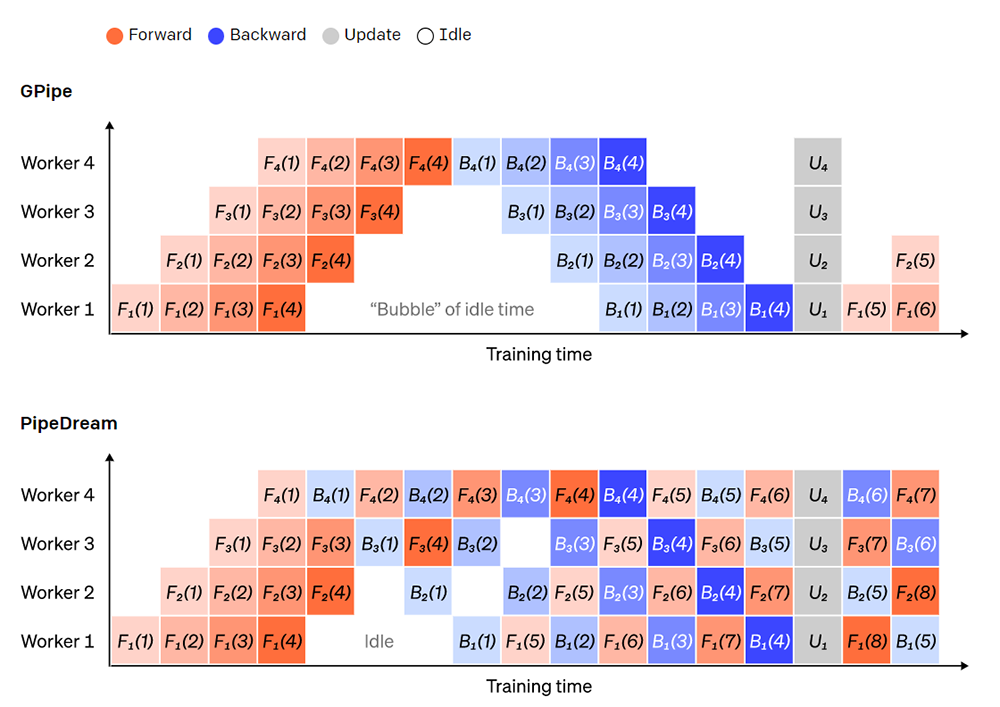
در طول گذر رو به جلو، بخشهای فعال فقط باید خروجی ( فعالسازی نامیده میشود ) لایههای آن را برای بخش فعال بعدی ارسال کنند. در طول گذر رو به عقب، فقط گرادیانهای موجود در آن فعال سازیها را برای بخش فعال قبلی ارسال میکند. فضای طراحی بزرگی برای نحوه زمانبندی این گذرها و نحوه جمعآوری گرادیانها در میکروبچ وجود دارد. GPipe هر فرآیند بخش فعال را به صورت متوالی رو به جلو و عقب میگذراند و سپس گرادیانها را از چندین میکروبچ به طور همزمان در پایان جمع میکند. PipeDream در عوض هر بخش فعال را به طور متناوب برای پردازش گذرهای رو به جلو و عقب برنامه ریزی میکند.
موازی سازی تانسور
در موازی سازی خط لوله یک مدل را به صورت “عمودی” به لایه تقسیم میکند. همچنین میتوان عملیاتهای خاصی را به صورت «افقی» در یک لایه تقسیم کرد که معمولاً به آن آموزش موازی تنسور میگویند. برای بسیاری از مدل های مدرن (مانند ترانسفورماتور)، گلوگاه محاسباتی، حاصلضرب یک ماتریس بَـچ – batch matrix – فعال سازی با یک ماتریس وزنی بزرگ است. ضرب ماتریسی را میتوان به عنوان حاصل ضرب نقطهای بین جفت سطر و ستون در نظر گرفت. میتوان حاصلضرب نقطهای کامل و مستقل را روی پردازندههای گرافیکی مختلف محاسبه کرد، یا بخشهایی از هر محصول حاصلضرب نقطهای را روی پردازندههای گرافیکی مختلف محاسبه کرد و در نهایت نتایج را جمعبندی کرد. با هر یک از این استراتژیها، میتوانیم ماتریس وزنی را به “shards (ماتریسهای ریز)”هایی با اندازه یکسان تقسیم کنیم، هر قطعه را روی یک GPU متفاوت میزبانی کنیم، و از آن shards برای محاسبه بخش مربوطه از حاصل کلی ماتریس قبل از برقراری ارتباط بعدی برای ترکیب نتایج استفاده کنیم.
به عنوان مثال میتوان Megatron-LM را نام برد که حاصل ضربهای ماتریس را در لایههای خودتوجهی( در یادگیری ماشین ) و MLP ترانسفورماتور موازی سازی میکند. PTD-P از موازی سازی تنسور، داده و خط لوله استفاده میکند. جدول زمانبندی خط لوله آن چندین لایه غیر متوالی را به هر دستگاه اختصاص میدهد، که سربار حباب را به قیمت ارتباطات شبکه بیشتر کاهش میدهد.
گاهی اوقات ورودی به شبکه را میتوانیم در طول یک بعد با درجه بالایی از محاسبات موازی نسبت به ارتباط متقابل موازی سازی کرد. یکی از این ایدهها توازی توالی است، که در آن یک دنباله ورودی در طول زمان به چندین نمونه فرعی تقسیم میشود و با اجازه دادن به محاسبات با نمونههایی با اندازه دانهبندی بیشتر، مصرف حافظه اوج را به طور متناسب کاهش میدهد.
Mixture-of-Experts (MoE) یا ترکیبی از بهترینها
با رویکرد Mixture-of-Experts (MoE)، تنها کسری از شبکه برای محاسبه خروجی برای هر ورودی استفاده میشود. یکی از روشهای قابل مثال، داشتن مجموعهای از وزنها است و شبکه میتواند در زمان استنتاج از طریق مکانیسم دروازهای انتخاب کند که از کدام مجموعه استفاده کند. این کار پارامترهای بسیار بیشتری را بدون افزایش محاسباتی امکان پذیر میکند. هر مجموعهای از وزنها به عنوان “بهترین” نامیده میشود، به این امید که شبکه یاد بگیرد که محاسبات و مهارتهای تخصصی را به هر بک از متخصص این روشها اختصاص دهد. بهترین روشهای مختلف را میتوان بر روی پردازندههای گرافیکی مختلف میزبانی کرد و مسیر و روشی واضح برای افزایش تعداد پردازندههای گرافیکی مورد استفاده برای یک مدل ارائه میدهد.
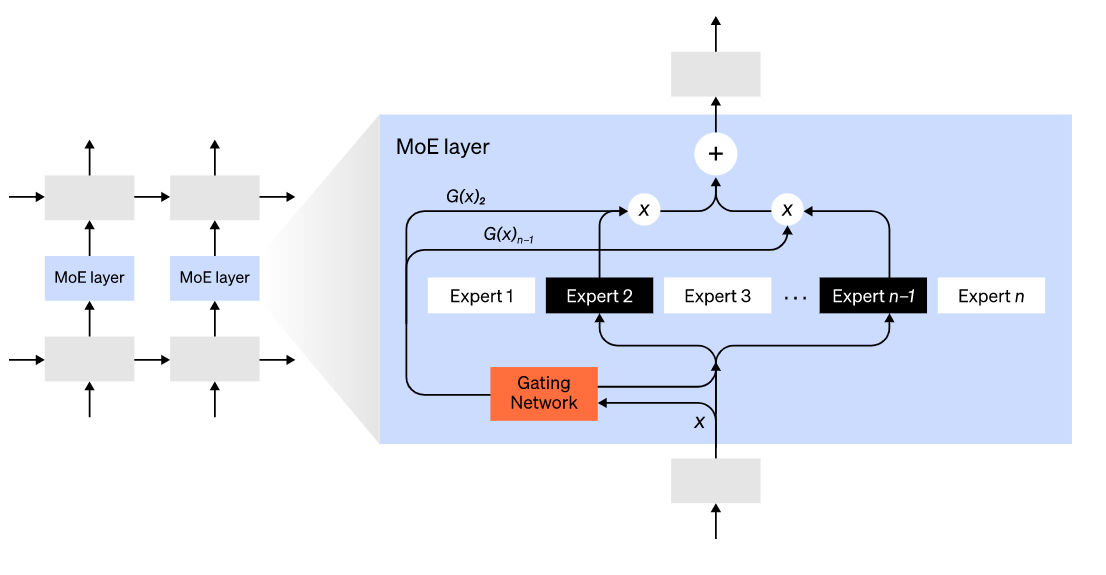
تصویر لایه ترکیبی از متخصصان (MoE). فقط 2 نفر از n کارشناس توسط شبکه دروازه انتخاب می شوند. (تصویر اقتباس شده از: Shazeer et al., 2017)
GShard یک ترانسفورماتور MoE را تا 600 میلیارد پارامتر با طرحی که در آن فقط لایههای MoE در چندین دستگاه TPU تقسیم میشوند و لایههای دیگر کاملاً کپی میشوند، مقیاس میدهد. با مسیریابی یک ورودی به یک متخصص، اندازه مدل مقیاس سوئیچ ترانسفورماتور را به تریلیونها پارامتر با پراکندگی بالاتر تغییر دهید.
سایر طرحهای ذخیرهسازی حافظه
بسیاری از استراتژیهای محاسباتی دیگر نیز وجود دارند که آموزش شبکههای عصبی بزرگ را قابل حملتر میکنند. مثلا:
برای محاسبه گرادیان، باید فعالسازیهای اصلی را ذخیره کرده باشید، که میتواند مقدار زیادی رم دستگاه را مصرف کند. چک پوینت (همچنین به عنوان محاسبه مجدد فعال سازی شناخته می شود) هر زیر مجموعه ای از فعال سازی ها را ذخیره می کند، و فعال های میانی را به موقع در طول پاس به عقب محاسبه می کند. این باعث صرفه جویی در حافظه زیادی با هزینه محاسباتی حداکثر یک پاس به جلو کامل اضافی می شود. همچنین میتوان به طور مداوم بین هزینه محاسباتی و حافظه با محاسبه مجدد فعالسازی انتخابی مبادله کرد، که عبارت است از بررسی زیرمجموعههایی از فعالسازیهایی که ذخیرهسازی نسبتاً گرانتر اما محاسبه آن ارزانتر است.
سایر طرحهای ذخیرهسازی حافظه
بسیاری از استراتژیهای محاسباتی دیگر نیز وجود دارند که آموزش شبکههای عصبی بزرگ را قابل حملتر میکنند. مثلا:
- برای محاسبه گرادیان، باید فعالسازیهای اصلی را ذخیره کرده باشید، که این کار میتواند مقدار زیادی از رم دستگاه را مصرف کند. چک پوینت (یا نقاط بررسی همچنین به عنوان محاسبه مجدد فعال سازی شناخته میشود) هر زیر مجموعهای از فعال سازیها را ذخیره میکند، و فعالهای میانی را به موقع در طول گذر به عقب محاسبه میکند. این باعث صرفه جویی در حافظه زیادی با هزینه محاسباتی حداکثر یک گذر به جلو کامل اضافی میشود. همچنین میتوان به طور مداوم بین هزینه محاسباتی و حافظه با محاسبه مجدد فعالسازی انتخابی مبادله کرد، که عبارت است از بررسی زیرمجموعههایی از فعالسازیهایی که ذخیرهسازی نسبتاً گرانتر اما محاسبه آن ارزانتر است.
- آموزش دقیق ترکیبی برای آموزش مدلها با استفاده از اعداد با دقت کمتر (معمولاً FP16) است. شتاب دهنده های مدرن می توانند با اعداد با دقت کمتر به تعداد FLOP بسیار بالاتر برسند و همچنین در RAM دستگاه صرفه جویی خواهید کرد. با مراقبت مناسب، مدل حاصل تقریبا هیچ دقتی را از دست نمیدهد.
- Offloading عبارت است از بارگذاری موقت دادههای استفاده نشده در CPU و یا در بین دستگاههای مختلف و بعداً دوباره بازخوانی آنها در صورت نیاز. پیادهسازیهای ساده سرعت آموزش را بسیار کاهش میدهند، اما پیادهسازیهای پیچیده دادهها را از قبل واکشی میکنند تا دستگاه هرگز نیازی به انتظار نداشته باشد. یکی از پیادهسازی این ایده ZeRO میباشد که پارامترها، گرادیانها و حالتهای بهینهساز را در تمام سختافزارهای موجود تقسیم میکند و در صورت نیاز آنها را عملی میکند.
- بهینه سازهای حافظه کارآمد، برای کاهش ردپای حافظه از وضعیت در حال اجرا حفظ شده توسط توسط بهینه کنندهها، مانند آدافکتور، پیشنهاد شدهاند.
- فشرده سازی همچنین میتواند برای ذخیره سازی نتایج میانی در شبکه استفاده شود. به عنوان مثال، Gist فعالسازیهایی را که برای گذر به عقب ذخیره میشوند، فشرده میکند. DALL·E گرادیانها را قبل از همگام سازی فشرده میکند.